everything works until you get clever with indexing
At ThriveDesk, we move a lot of customer conversations, and we use Meilisearch to keep searching over them fast. One quiet afternoon, in the middle of a reindex job, it threw this at me:
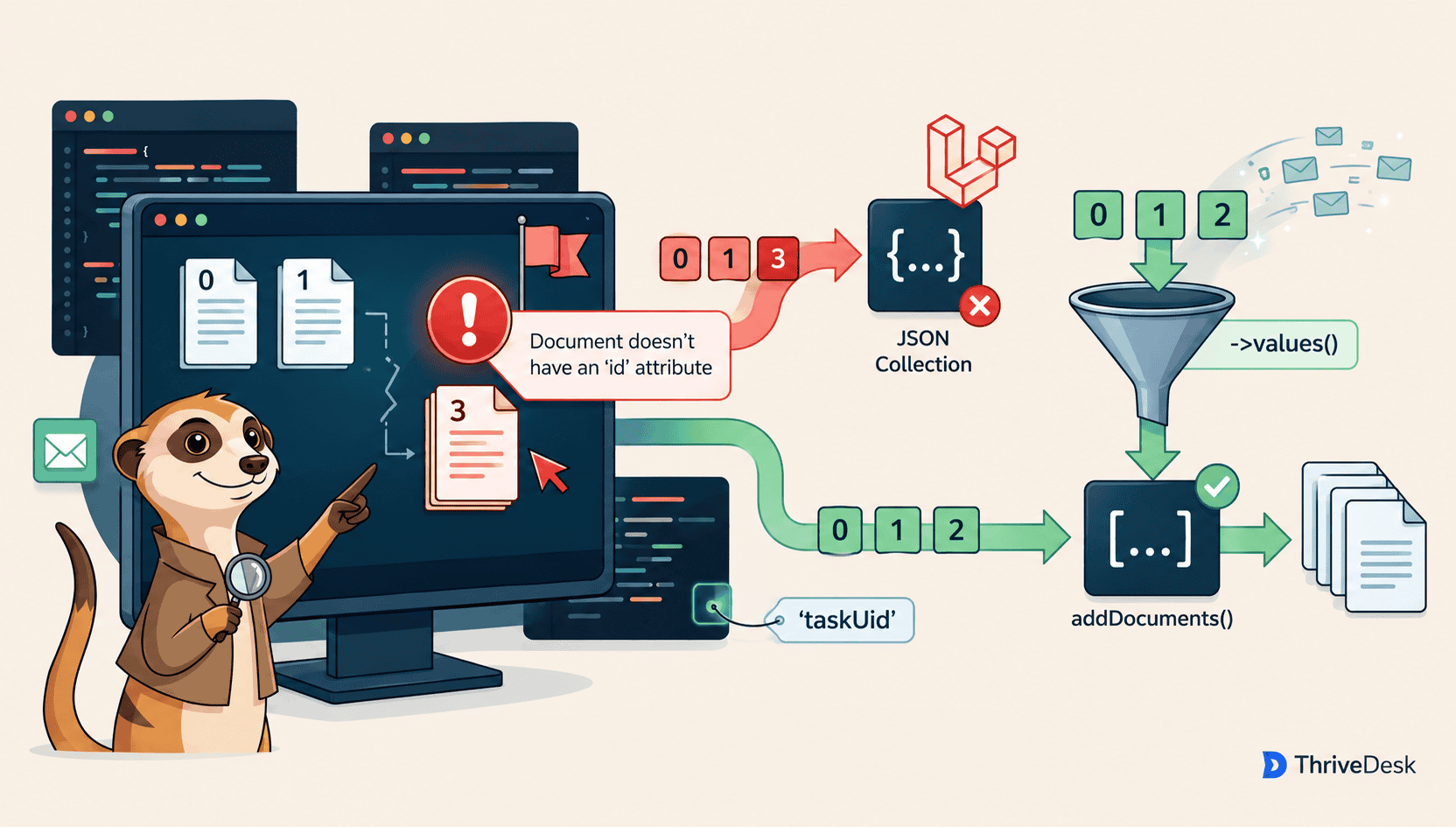
Document doesn't have an `id` attributeEvery document in the batch had an id, so a “document doesn't have an id attribute” error made no sense. I checked twice. The error turned out to be entirely my fault, and fixing it meant dropping one of Laravel Scout’s conveniences and talking to Meilisearch directly. Here’s what happened.
Why not just use Laravel Scout?
Scout is the easy path when all you want is “keep this model in sync with the index” to mark the model searchable and forget about it. The catch is that Scout hides the thing we care about once volume goes up, the task ID.
Every async operation in Meilisearch, like adding or deleting documents, returns a taskUid. You can poll that ID to find out whether the work actually landed. Scout doesn’t surface it. When you’re pushing thousands of conversations through a pipeline, “I called searchable() , so it probably worked” isn’t a monitoring strategy. We wanted to record every enqueued task, retry those that failed, and check the actual state of the index.
So we skip Scout’s helper and call Meilisearch’s addDocuments() and deleteDocuments() ourselves through the underlying engine, then grab the taskUid and store it.
The actual bug: a sparse array
I was batching conversations to index, and some of them were duplicates, so I dropped the duplicates with ->unique(). The result looked like this:
$filtered = collect([
0 => ['id' => 1],
1 => ['id' => 2],
3 => ['id' => 4], // index 2 is gone
]);Every element still has an id, so at a glance it looks fine. But look at the keys: 0, 1, 3. When unique() removed the duplicate at index 2, it kept the original keys and left a hole. The array is now sparse, and that hole is the whole problem. The reason it breaks is PHP, not Meilisearch.
When json_encode() gets an array whose integer keys run 0, 1, 2, … with no gaps, it outputs a JSON array:
[{"id":1},{"id":2},{"id":4}]Put a gap in those keys, and PHP can’t treat it as a list anymore, so it falls back to encoding a JSON object instead:
{"0":{"id":1},"1":{"id":2},"3":{"id":4}}addDocuments() expects an array of documents. Give it an object, and it reads the entire payload as a single document, whose top level fields are “0”, “1”, and “3”. That one document has no id field, so the error was telling the literal truth. I’d handed it the wrong shape.
The fix
->values() throws away the keys and renumbers them from zero, which is enough to get a JSON array back:
$task = $engine->index($this->index)->addDocuments(
$uniqueSearchableDocuments->filter()->values()->all(),
(new Conversation)->getKeyName()
);Same thing on the delete path:
$task = $engine->getIndex($this->index)->deleteDocuments(
$shouldMakeUnsearchable->values()->all()
);The second argument addDocuments() is the primary key name. We read it off the model getKeyName() instead of hardcoding id, so it keeps working if that ever changes.
The Main Takeaways
filter() and unique() keep the collection’s original keys. That’s deliberate, and inside Laravel it’s usually what you want. It stops being what you want the moment the data leaves PHP for an external API, so get in the habit of calling ->values() after either one when you’re about to serialize.
It’s also a decent reminder that bugs like this live at the boundary between systems. It read like a Meilisearch problem right up until I looked at the actual JSON, at which point it was clearly a serialization problem I’d made myself.
And if you actually need to know whether your indexing worked, searchable() won’t tell you. Calling the Meilisearch methods directly is more code, but it’s the only way to get the taskUid and build retries on top of it.
How the pipeline runs in production
A BatchTask row drives each batch. Searchable tasks load the conversations, dedupe them, reset the keys with values(), call addDocuments(), and save the returned taskUid. Unsearchable tasks load the targets, reset keys, call deleteDocuments(), and save the taskUid same way. The diagram below shows both paths.

Tracking the taskUid per batch has paid off. We can tell whether a batch succeeded or failed instead of assuming it worked. Failed tasks get retried with an attempt counter, and the values() fix also cleared out a pile of false positive errors that had been adding noise to our logs.
Closing thought
Search infrastructure looks simple until you run it at scale, and then the small assumptions are the ones that get you. This was a Laravel collection that looked like valid JSON and wasn’t, the moment it crossed into Meilisearch.
So if you take one thing from this, after you filter or dedupe a collection that’s headed for an external system, call ->values(). It’s cheap, and it’ll save you an afternoon.
We do a fair amount of this at ThriveDesk. Like batching, async task tracking, and embeddings for semantic search. If you’re wiring up Laravel and Meilisearch and want to compare notes, get in touch.